H-IIA 47号機が打ち上げられ、相乗りだったX線観測衛星XRISMと月着陸機SLIMがともに正常に分離された。始まったばかりだが、最初のハードルを越えたという感じ。
https://www.jaxa.jp/press/2023/09/20230907-1_j.html
日本初、世界で5か国目(ソ・米・中・印の次)の月軟着陸を目指すSLIMも非常に大事だが、自分はXRISMの方に思い入れがある。XRISMの高分解能X線分光器「Resolve」は実質的に3回連続で死んでいる、ISASにとって悲願の観測装置だから。
天文学の観測の柱として、画像を撮る「撮像」と天体のスペクトルを得る「分光」がある。今は両方同時にできる撮像分光装置というのもよくある。X線の分光器にもいろいろあるが、Resolveはマイクロカロリメーターという方式で、X線光子を受けて素子の温度が上がるのを精密に測定して光子のエネルギーを決める。波長(エネルギー)の分解能 E/ΔE が数百〜1000くらいと非常に良いが、液体ヘリウムを使って10-2Kという極低温まで装置を冷やす必要がある。
日本のX線観測衛星は、4代目の「あすか」(ASTRO-D) が1993年に上がって、これは2001年まで大活躍した。あすかの分光器は2種類搭載されていたが、これらはガス蛍光比例計数管とCCDを使う方式で、E/ΔE は10-50程度。
あすか以降の日本のX線衛星の歴史は血塗られた道だった。5代目になるはずだった「ASTRO-E」は2000年にM-V 4号機で打ち上げられ、初めてX線マイクロカロリメーター分光器「XRS」が搭載された。しかし第1段の姿勢が異常になって地球周回軌道に乗らず、失敗。ASTRO-Eは「ひりゅう」と名付けられるはずだったという1。
ASTRO-Eの代替機「すざく」(ASTRO-EII) は2005年に打ち上げられ、5代目X線衛星として2015年まで運用されて大きな成果を挙げた。しかし肝心のXRSは打ち上げのわずか1か月後に液体ヘリウムが蒸発してしまい、試験観測を始める前に使えなくなってしまった。なので、X線マイクロカロリメーター分光器で天体を観測した実績はここでも作れず。
続く「ひとみ」(ASTRO-H) は2016年に打ち上げられ、これも打ち上げ自体は成功した。しかし軌道投入から38日後に機体が異常回転を始め、遠心力で機体全体がばらばらに破壊されて運用終了。ただし打ち上げ約2週間後から観測機器のチェックが始まっていたため、ASTRO-H搭載のX線マイクロカロリメーター分光器「SXS」は、ぎりぎりペルセウス座銀河団の観測データだけは取れている。素晴らしい分解能のスペクトルで、この成果だけでNatureの論文になった2。
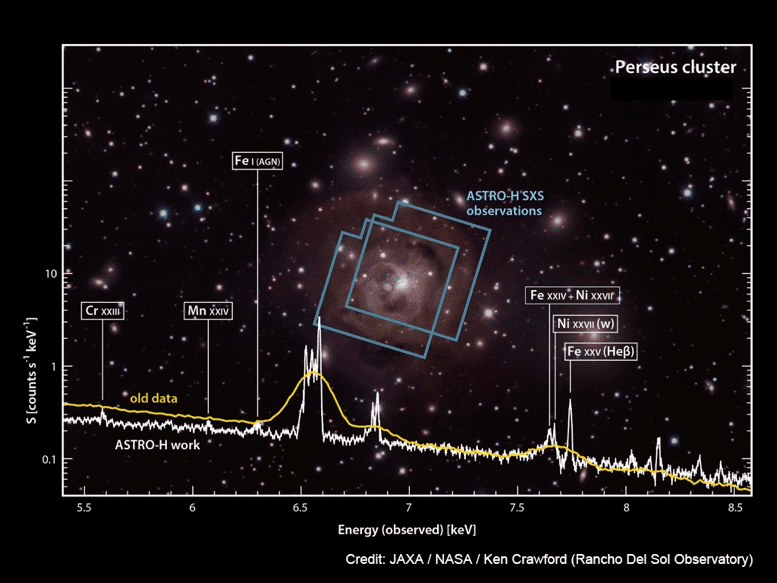 白がASTRO-HのSXSによるスペクトル。黄色は「すざく」によるX線CCD分光器でのスペクトル。(宇宙のレシピを手に入れよう −銀河から銀河団まで|XRISM)
白がASTRO-HのSXSによるスペクトル。黄色は「すざく」によるX線CCD分光器でのスペクトル。(宇宙のレシピを手に入れよう −銀河から銀河団まで|XRISM)
…というように、マイクロカロリメーター分光器は過去3回とも設計寿命を全うしておらず、今回のXRISMが4回目の搭載となる。ASTRO-HのSXSとXRISMのResolveは、万一ヘリウムが抜けてしまっても冷凍機で0.05Kまで冷やして観測できる冗長性を備えている。
観測装置の名前はたいていは頭字語だが、今回「Resolve」と名付けられているのは、波長を「分解」するという意味以外に「決意する」「決着を付ける」といった意味も込めているからだと言われている3。
他国のX線観測衛星というとNASAの「Chandra」と欧州の「XMM-Newton」が有名だが、それぞれの高分解能分光器の波長域と分解能を比べると以下の通り(低分解能の分光器の比較は略)。XRISMはChandra, XMM-Newtonよりも高エネルギーの領域でエネルギー分解能がより高い。
| Chandra4 | Chandra | XMM-Newton5 | XRISM6 |
| 装置 | HETG | LETG | RGS | Resolve |
| 波長域 | 0.4-10 keV | 0.07-0.2 keV | 0.35-2.5 keV | 0.3-12 keV |
| 分解能 (E/ΔE) | 〜800 @ 1.5 keV
〜200 @ 6 keV | > 1000 | 200-800 | > 850 @ 6keV
(ΔE < 7 eV) |
ということで、XRISMが無事に観測を開始し、寿命を全うすることを祈っております。
